

皆さんこんにちは。ラネクシー社員Kです。
今回は、コンテンツ認識ルールを使用して「マイナンバー」のデータを含むファイルを識別し、外部デバイスへの書き出しを制御する機能について考察してみましょう。
「コンテンツ認識ルールって、何だっけ?」とおっしゃる方は、お手数ですが、まず本コラムの 第11回 「コンテンツ認識ルール」って何? をご覧いただき、予習をお願いします🙇
第11回では、コンテンツ認識ルールの中でも「ファイルタイプ検知」という、BASEライセンスに含まれる機能についてお話ししました。
簡単にまとめますと、特定のファイルタイプ(どのような性質のファイルなのか)について、これを特定のデバイスに書き出させないなどのルールを作り、ユーザーさんの操作を細かく規制しよう、というのがこの機能の趣旨でした。
今回はいよいよ「ContentLock」というオプションを導入します!
オプションライセンスについて詳しく知りたい方は、第6回 DeviceLockのライセンス をご覧いただくとよろしいかと思います。
さて、今回のテーマである「マイナンバーを検出する」ためには、次のどちらかの準備が必要です。
- BASEライセンスとContentLockライセンスを同時に購入して適用する
- ご利用中のBASEライセンスに、ContentLockオプションライセンスを追加で購入して適用する
いずれの場合も、ContentLockオプションライセンスは、BASEライセンスと同数が必要です。
では、まずは「マイナンバー」から。
第8回 USBデバイスの識別IDとは? で少しだけ触れていますので、ここに引用させていただきます。
日本に住民票がある人なら全員、「マイナンバー」と呼ばれる個人番号を一人に一つずつ持っています。
この番号は重複しないように決められていますので、マイナンバーで個人識別ができるようになっています。マイナンバーは12桁の数字で構成されているのですが、まず住民票コードから非公開の計算式で生成される左11桁の数字があって、次にこの11桁を使ってムズカシイ計算をすることで1桁の検査用数字(※)というものを導き出し、これを合わせた12桁をマイナンバーとしています。
- 検査用数字は左11桁の数字の妥当性を判定するもので、コンピューターにマイナンバーを入力する際のタイプミスの防止などに役立ちます。

詳しくは私にもよくわかりませんが、とにかく「単なるランダムな12桁の数字」ではなく、何らかの規則性がありそうなことはわかりますね。
1. そもそも、コンテンツ認識ルールでマイナンバーは識別できる?
コンテンツ認識ルールは、ファイルなどのコンテンツの中身を調べ、それがあらかじめ設定されている条件に該当する場合に、書き出し制御などを行なう機能です。
ファイル中にマイナンバーのデータが含まれているかどうかを識別するにはどうしたらよいでしょうか。
2つのケースを考えてみましょう。
- ファイル中に「マイナンバー」という文字列があるかどうかを調べる
もしワープロ文書や表計算シートの中に「マイナンバー」という文字列があったら、このファイルにはマイナンバーのデータが格納されているかもしれません。 - ファイル中に12桁の数字の羅列があるかどうかを調べる
もしワープロ文書や表計算シートの中に12桁の数字の羅列があったら、この数列はマイナンバーのデータかもしれません。
まず①について。
ファイル中の「マイナンバー」という文字列を検出するには、コンテンツ認識ルールの「キーワード」識別機能を使います。
「キーワード」識別機能は、あらかじめ指定しておいた文字列がファイル中に存在しているかをスキャンして検知するものです。
こんな感じの簡単な設定です。
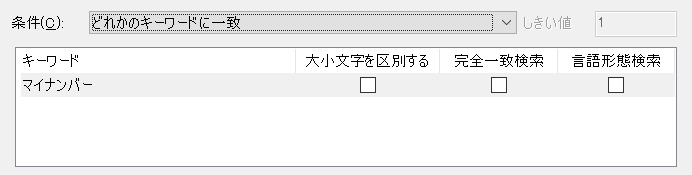
「マイナンバー」というキーワードを登録するだけです。
この条件でルールを作り、ファイルを検査するわけです。
続いて②について。
ファイル中の12桁の数字の羅列を検出するには、コンテンツ認識ルールの「パターン」識別機能を使います。
「パターン」識別機能は、あらかじめ指定しておいた正規表現に適合する文字列がファイル中に存在しているかを検知するものです。
次のように、12桁の数列を表す正規表現を指定します。

12桁の数列を表す正規表現を、ここでは [0-9]{12} のように指定しています。
この条件でルールを作り、ファイルを検査するわけです。
ついに「正規表現」が出てきましたね。今回のような簡単なものは私でもなんとかできますが、複雑怪奇なものは、手に負えません・・。
私のように、正規表現はあまり得意でないな、とおっしゃる方も多いのかなと思いますが、もし今回の記事に関心をお持ちいただけましたら、まずは簡単なものからチャレンジしてみましょう!
最後に、①と②の複合条件。
「マイナンバー」という文字列と「12桁の数列」の両方を含むファイルを検出するには、①と②の条件を AND で結合します。
「マイナンバー」という文字列と「12桁の数列」のどちらかを含むファイルを検出するには、①と②の条件を OR で結合します。
このように、とても簡単な設定でマイナンバーを検出できます!
・・・って、簡単に言い切ってしまいましたが、本当にこれで良いのでしょうか。
2. マイナンバーの検査用数字
①や②で検出できるのは、「マイナンバー」という文字列や、12桁の数列だけです。
これらは本当にマイナンバーのデータなのでしょうか?
「マイナンバー」文字列はもちろん、12桁の数字があれば何でもマイナンバーのデータ、ということにはならないと思います。
12桁の数列があるからといって何でも「マイナンバー」と検出してしまったら、本当はマイナンバーに関係ないファイルを、マイナンバーを含むファイルと誤検知してしまう確率が非常に高くなってしまうのではないでしょうか。
運転免許証の番号や宅配便の送り状番号など、12桁の数列を設定しているものは他にもいろいろありそうですね。みんな大切な番号ではありますが・・。
では、マイナンバー12桁のうち最後の1桁である「検査用数字」を、マイナンバーデータの特定に利用することはできないでしょうか。
検査用数字は、マイナンバーの左11桁の数字を使った計算から導き出される1桁の数字です。
幸いこの計算式は公開されていますので、もしかしたら役に立つかもしれません。
ムズカシイ計算のようで、文系の私には到底理解できませんが、興味のある方は調べてみるとよろしいかと思います。
とにかく、この検査用数字を計算して照合することで、ある12桁の数列がマイナンバーであると推測した場合の「当たり」の確率が上がりそうな気がしませんか。
たとえば、マイナンバー12桁のうち左の11桁が「12345678901」の場合、計算された検査用数字は「8」になります。
ですから、12桁の数列があって、「123456789018」だったらこれがマイナンバーである可能性があります。
逆に、「123456789010」だったり「123456789014」のように右端の数字が「8」以外であればマイナンバーでないことになります。
これにより、12桁の数列から、確実にマイナンバーでないものを排除することで、「はずれ」の確率を下げることができるのです。
残念ながら、「123456789018」であっても、必ずしもマイナンバーとは限りませんので、「的中率100%」を歌い上げることはできませんが・・。
コンテンツ認識ルールは、ファイル検査の際にこの検査用数字の計算を実施することで、マイナンバーの検出精度を上げる機能を持っています。
- 上にも書きましたが、「12桁の数列で右端の数字が計算上検査用数字と一致している」だけでは、この数字がマイナンバーと断定することはできません。ですので、どんなに精度の高い検出システムでも、「100%マイナンバー」と断定するのは非常に難しいと思います。
3. マイナンバー検出の設定
ここで、コンテンツ認識ルールでマイナンバーを検出するための実際の定義を見てみましょう。
本コラムの性質上、設定手順の説明にまでは踏み込みませんが「なんとなく」でも雰囲気がお分かりいただけるかと思います。
- ラネクシーでは、ゆるい本コラムとは違って実用的な資料として「How to DeviceLock」という、DeviceLock関連の別のコンテンツをご用意しております。ここに設定手順の説明がありますので、詳しい設定手順をご確認されたい場合は「32:マイナンバーを含むファイルの書き出しを禁止するには?」をご覧いただくとよろしいかと思います。
実は、マイナンバーの定義は、コンテンツ認識ルールにあらかじめ登録されています。
その画面はこんな感じで、マイナンバーの条件をこんな情報として定義しています。
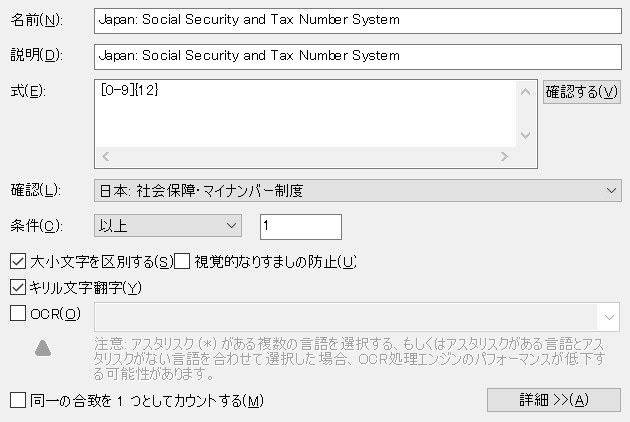
肝心なのは「式」と「確認」と「条件」の部分です。
「式」のところを見ると [0-9]{12} ってありますね。これは、0から9までの数字が12桁連続している、といった意味の正規表現です。
これだけだと、「12桁の数列がある」ことしか検出できません。
先ほどご説明しました検査用数字の妥当性を含めてマイナンバーデータを検出するには、「確認」のプルダウンメニューから「日本: 社会保障・マイナンバー制度」を選んでおきます。
ここには、検査用数字の計算プログラムが仕込まれていて、12桁の数列を検知すると、その数字が計算プログラムに送られて検査用数字を算出するのです。
この「式」と「確認」の併用により、「12桁の数列で、かつ12桁目の数字がマイナンバー検査用数字の計算式で求められる値と同じになる」条件が定義されました。
最後に「条件」ですが、これはどういうもので、何のためにあるのでしょう。
たとえば、一つの文書の中に、上記の条件に該当する箇所が1か所しかない場合、「これはマイナンバーを含む文書」と判断できるでしょうか。
マイナンバーは個人の番号ですから、普通、マイナンバーを管理するなら個人単位ではなく、組織の皆さんのマイナンバーを一つの文書に入れて管理することが多いかと思いますが、如何でしょうか。
そうだとすると、逆に一つの文書に「12桁の数列で、かつ12桁目の数字がマイナンバー検査用数字の計算式で求められる値と同じになる」数列が一つしかない場合、マイナンバーと同じ要件を満たす数列が「たまたま」書き込まれていた、と考えるのが普通ではないかと思います(必ずしもそうとは限りません、念のため)。
そこで、「一つの文書にマイナンバーと同じ要件を満たす数列がいくつあったらマイナンバーを含むとみなすか」という「しきい値」の指定をして、マイナンバー検出の精度を上げようという設定がこれです。
上の画面では「以上」「1」となっているので「一つの文書にマイナンバーと同じ要件を満たす数列が一つ以上あったらマイナンバーを含むとみなす」という定義になりますが、ここは自由に設定変更することができます。
たとえば、「10以上」に設定すると、「一つの文書にマイナンバーと同じ要件を満たす数列が10以上あったらマイナンバーを含むとみなす」となります。
4. コンテンツ認識ルールの「パターン」
このようにして定義された条件は、デバイス制御のルール(コンテンツ認識ルール)に組み込まれ、外部デバイスなどへの書き込み制御の詳細な条件として利用されます。
いかがでしたでしょうか。
今回はマイナンバーを例にとり説明しましたが、コンテンツ認識ルールの「パターン」検出機能は、正規表現だけでなく、このような組み込み済みの計算機能との併用で、検出精度を上げる工夫が凝らされています。
もちろん正規表現だけでパターンを構成することもでき、必要な条件で独自のパターンを設定して、コンテンツ認識ルールで利用することもできるようになっています。
また、マイナンバーのほかにも、クレジットカード番号や電子メールアドレス、電話番号など、数多くのパターンがあらかじめ定義されています。
DeviceLockには無料でご試用いただけるトライアルバージョンもあります。
今回ご紹介した機能もご試用いただけますので、ぜひ一度お試しください!
ではまた。
- « 前の記事へ
- でばいすろっくコラムTOP
- 次の記事へ »
投稿日:2021年03月19日
でばいすろっくコラム 記事一覧
- 第20回 DeviceLockマスターへの道
- 第19回 DeviceLockのピリ辛機能
- 第18回 不思議な差の世界
- 第17回 テレワークとDeviceLock
- 第16回 マイナンバーを検出する
- 第15回 DeviceLockの集中管理
- 第14回 レガシーデバイスとDeviceLock
- 第13回 DeviceLockの管理のしくみ
- 第12回 一時的ホワイトリストによるUSBデバイスの一時許可
- 第11回 「コンテンツ認識ルール」って、なに?
- 第10回 「DeviceLock Lite」とは?
- 第9回 「シャドウイング」ログって、なに?
- 第8回 USBデバイスの識別IDとは?
- 第7回 アクセスの記録を監査ログに残す
- 第6回 DeviceLockのライセンス
- 第5回 光学ドライブのアクセス制御
- 第4回 トライアルのススメ
- 第3回「USBを止める」って、どういうこと?
- 第2回 DeviceLockのしくみ
- 第1回 パソコンとデバイス
- でばいすろっくコラムとは?
国内5800社、40万台の導⼊実績のデバイス制御ソフト︕
内部からの情報漏えいを防ぐDLPソリューション" DeviceLock ( デバイスロック)"
DeviceLock(デバイスロック)はユーザーに負担を強いずに必要なデータだけを守るDLP(Data Loss Prevention)ソリューションです。PCのUSBポート、CD/DVDドライブ、タブレット端末などの外部デバイス制御に加え、インターネットを介したファイルのコピー、送信を制御し、個人情報や情報資産などの不正持ち出しや盗難・紛失による情報漏えいを防止します。
DeviceLockは国内5800社、40万台の導入実績を持ち、外部デバイス制御パッケージの分野でシェアNo.1※のツールです。
- ミック経済研究所「サイバーセキュリティソリューション市場の現状と将来展望2019 データ保護編」より
